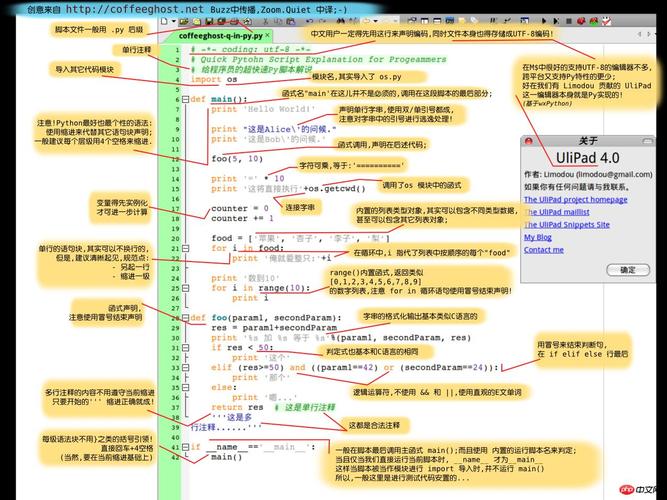
本篇目录:
- 1、如何用python的selenium提取页面所有资源加载的链接
- 2、selenium怎么获取不规则下拉列表所有元素
- 3、python+selenium怎么读取csv中的数据进行列表循环登录自动化参数登录...
- 4、selenium超全教程(4)-持续更新中
- 5、selenium怎么获取网页标签个数?
如何用python的selenium提取页面所有资源加载的链接
选择用selenium,但是没找到selenium的webdriver下取得所有资源加载链接的方法。selenium包下有一个selenium模块。查看源码时看到有个get_all_links方法。但是一直没找到这个模块的用法。最后,求解谢谢大家。
安装Python和相关库 要使用Python进行网页数据抓取,首先需要安装Python解释器。可以从Python官方网站下载并安装最新的Python版本。安装完成后,还需要安装一些相关的Python库,如requests、beautifulsoup、selenium等。
-图1")
这个可以通过浏览器自带的f12 。或者通过鼠标右键,审计元素获得当前html源代码。步骤如下:使用框架载入形式,代码如下:代码解析:src="12htm" 载入的页面 。
你可以使用scrapy, python的爬虫框架,或者如果你只是抓取比较简单的页面,可以使用requests这个python库,功能也足够用了。
selenium + phantomjs 模拟点击按钮,或者另写代码实现js函数openVideo();顺着第一步再去解析新页面,看看能否找到视频的原始地址;假设视频的原始地址第二步找到了,在通过视频的原始地址下载视频就OK啦。
-图2")
办法:获取页面上所有元素属性包含href的元素,可以用getAttribute(“href”)方法,然后做个循环依次点击。Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
selenium怎么获取不规则下拉列表所有元素
1、Selenium封装了Select类专门处理下拉框。定义了通过下标,通过文本,通过值等方法选择相对于的项。
2、当前值直接获取text就行了。下拉值就获取一共几个div,然后获取一下div的text属性。
-图3")
3、标签select :需要用到 Select类 ,先要导入select方法, from selenium.webdriver.support.select import Select input标签 :通常的处理方式与其他的元素类似,点击或使用JS等。
4、我用的比较笨的办法,先点击那个输入框,然后等待列表出现之后,点击列表中的元素。
python+selenium怎么读取csv中的数据进行列表循环登录自动化参数登录...
)命令行工具cd切换到所要安装的包的目录,找到setup.py文件,然后输入python setup.py install 2 不用pip或easy_install,直接打开cmd,敲pip install rsa。3 提升阶段需要恒心和耐力。
将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。
selenium超全教程(4)-持续更新中
1、Selenium打开一个页面之后,默认是在父页面进行操作,此时如果这个页面还有子页面,想要获取子页面的节点元素信息则需要切换到子页面进行擦走,这时候switch_to.frame()就来了。
2、)导入Selenium的java客户端和selenium-server.jar包,如图所示;注意导入的路径就是步骤5 下载的2个包的存放路径。
3、selenium的意思是硒。基本信息 CAS号:7782-49-2E。INECS号: 231-957-4。元素名称:硒。中文读音:xī。元素符号:Se。元素英文名称:Selenium。元素类型:非金属元素。
4、本教程的目标是在使用Mozilla Firefox作为主浏览器的ubuntu上配置和运行selenium headless。安装Firefox headless 确认你的ubuntu安装的是最新版本的Firefox。我遇到过Selenium的版本和Firefox的版本不兼容问题。
selenium怎么获取网页标签个数?
您可以按照以下步骤来配置八爪鱼采集器进行数据采集: 打开八爪鱼采集器,并创建一个新的采集任务。 在任务设置中,输入要采集的网址作为采集的起始网址。 配置采集规则。
在这个示例中,我们首先导入了BeautifulSoup类,然后将之前获取到的网页内容html作为参数传递给BeautifulSoup类的构造函数,创建一个BeautifulSoup对象soup。通过soup.title.text属性可以获取网页的标题,并打印输出。
使用 Python 的 Requests 库请求网页,然后使用 Beautiful Soup 库进行页面解析,提取目标数据。 使用 Selenium 库模拟浏览器操作,通过 CSS Selector 或 XPath 定位特定元素,提取目标数据。
到此,以上就是小编对于selenium操作select的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏