本篇目录:
- 1、怎么把impala表导入kudu
- 2、hql语句怎么写向Hive中一次插入一条数据或一个字段的值,类似关系型数据...
- 3、怎样将文本文件导入impala中的分区表中
- 4、spark、hive、impala、hdfs的常用命令
- 5、Impala合并小文件
怎么把impala表导入kudu
你可以使用Java Client实时导入数据,同时也支持Spark(运算) impala(分析工具,比Hive快) MapReduce HDFS HBase 很容易从HDFS中获取数据,占用内存小于1G。
数据清洗:MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算。数据查询分析:Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供HQL(HiveSQL)查询功能。
-图1")
在Hive的运行过程中,用户只需要创建表,导入数据,编写SQL分析语句即可。剩下的过程由Hive框架自动的完成。 Impala Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。
hql语句怎么写向Hive中一次插入一条数据或一个字段的值,类似关系型数据...
1、目前我知道的方法是把你希望添加的数据写入到文本中,然后从文本导入到你的表格中。但是,hive不知道oracle的insert into , update。
2、插入数据:insertinto表名values(值列表)[,(值列表)];可以一次性插入多条数据。
-图2")
3、首先,打开sql查询器,连接上相应的数据库表,以stu2表添加一行数据为例。点击“查询”按钮,输入:insert into stu2(first_name, last_name, age, sex) values(赵, 六, 16, 1);。
4、(值1,值2,值3)【sql语句】:sql 语句是对数据库进行操作的一种语言。
5、有null 的表示字段允许零长 数据表(或称表)是数据库最重要的组成部分之一。数据库只是一个框架,数据表才是其实质内容。根据信息的分类情况,一个数据库中可能包含若干个数据表。
-图3")
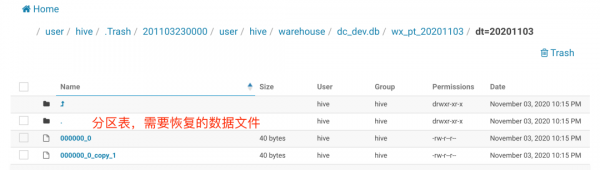
怎样将文本文件导入impala中的分区表中
1、可以直接在Access里选择‘打开‘文本文件,这样按照向导来导入一个文本文件到Access数据库中,然后使用编程的方法将其导入到最终的目标数据 库中。
2、打开EXCEL表格,点击菜单栏上数据,单击“获取数据-自文件-从文本”。打开资源管理器界面,选择要导入的文本文件。点击弹出对话框上右下角的“加载”。TXT文件中的数据转换成了EXCEL表格数据。
3、您好,方法 要将多个txt文本文件内容导入一个excel表格中,一般大家想到的方法就是使用vba来实现。今天,我们这里不使用vba,而是先使用dos命令来合并txt文件,再用excel数据导入功能。
4、在电脑上打开一个Excel表格,点击菜单栏“数据”选项,在出现的工具栏“获取外部数据”选择“自文本”选项后点击。点击后进入文件选取界面,找电脑中找到目标文本导入。文本文件内容如下图。
5、首先我们打开电脑,然后在电脑中打开WPS表格,进入主界面之后我们点击上方功能栏中的数据选项,然后点击下一行中的“导入数据”选项。
spark、hive、impala、hdfs的常用命令
1、和HIVE的ANALYZE TABLE类似,这个命令主要也是为了优化查询,加快查询的速度。本来IMPALA是依靠HIVE的ANALYZE TABLE的,但是这个命令不是很好用同时不稳定,所以IMPALA自己实现了个命令完成相同功能。
2、上次讲过HIVE 的一个常用命令 MSCK REPAIR TABLE , 这次讲讲HIVE的 ANALYZE TABLE 命令,接下来还会讲下Impala的 COMPUTE STATS 命令。这几个命令都是用来统计表的信息的,用于加速查询。
3、Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。
4、Sqoop:这个是用于把Mysql里的数据导入到Hadoop里的。当然你也可以不用这个,直接把Mysql数据表导出成文件再放到HDFS上也是一样的,当然生产环境中使用要注意Mysql的压力。
5、在hive-site-xml中把hive.execution.engine配置换成spark,在hive所在节点安装Spark并配置环境变量。外部远程登录或者hive命令行模式就会执行spark任务了。
Impala合并小文件
1、hadoop fs -mkdir /umtsd/test //在/umtsd目录下创建test目录 hadoop fs -put /home/data/u100csv /impala/data/u5002 //将home/data/u100csv这个文件put到hdfs文件目录上。
2、/etc/alternatives/impala找到impala的安装目录:/usr/lib/impala(4)配置Impala在Impala安装目录/usr/lib/impala下创建conf,将hadoop中的conf文件夹下的core-site.xml、hdfs-site.xml、hive中的conf文件夹下的hive-site.xml复制到其中。
3、合并所有Map的spill文件:TaskTracker会在每个map任务结束后对所有map产生的spill文件进行merge,merge规则是根据分区将各个spill文件中数据同一分区中的数据合并在一起,并写入到一个已分区且排序的map输出文件中。
4、文件采集:包括实时文件采集和处理技术flume、基于ELK的日志采集和增量采集等等。
5、kudu也是cloudera主导的项目,跟Impala结合比较好,通过impala可以支持update操作。kudu相对于原有parquet和ORC格式主要还是做增量更新的。Hbase Hbase使用的很广,更多的是作为一个KV数据库来使用,查询的速度很快。
6、除此之外,我们还可以通过设置hive的参数来合并小文件。
到此,以上就是小编对于impala批量查看表大小的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏