本篇目录:
- 1、spark、hive、impala、hdfs的常用命令
- 2、SparkSQL同步Hbase数据到Hive表
- 3、带的CSV文件如何导入hive
- 4、【数仓】对比spark-hive的两种分布式计算模式
spark、hive、impala、hdfs的常用命令
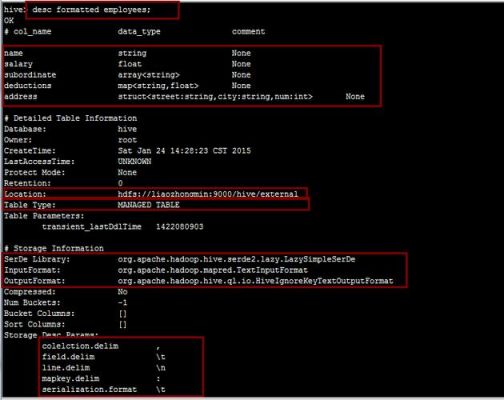
1、上次讲过HIVE 的一个常用命令 MSCK REPAIR TABLE , 这次讲讲HIVE的 ANALYZE TABLE 命令,接下来还会讲下Impala的 COMPUTE STATS 命令。这几个命令都是用来统计表的信息的,用于加速查询。
2、Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。
-图1")
3、要想使用Hive首先需要启动hadoop,因为hive的使用是依赖于hadoop的hdfs文件系统以及MapReduce计算的,下图是启动hadoop,如下图。
SparkSQL同步Hbase数据到Hive表
很多早期用户还会在数据仓库分析数据之前,采用Hadoop集群和NoSQL数据库存储数据。这些应用使用起来都很简单,就像用Hadoop分布式文件系统(HDFS)存储数据一样,也可以通过Hive,HBase,Cassandra和其他NoSQL技术建立更复杂的关联。
对于 SQLContext,唯一可用的方言是 “sql”,它是 Spark SQL 提供的一个简单的 SQL 解析器。在 HiveContext 中,虽然也支持”sql”,但默认的方言是 “hiveql”,这是因为 HiveQL 解析器更完整。
-图2")
讲MR输出数据到hive表的location分区目录,然后通过Sql添加分区即可。ALTERTABLEtable_nameADDPARTITION(partCol=value1)locationlocation_path换成自己的表,分区字段和path。
Iceberg官网定义:Iceberg是一个通用的表格式(数据组织格式),提供高性能的读写和元数据管理功能。 Iceberg 的 ACID 能力可以简化整个流水线的设计,传统 Hive/Spark 在修正数据时需要将数据读取出来,修改后再写入,有极大的修正成本。
Hive On Spark做了一些优化:Map Join Spark SQL默认对join是支持使用broadcast机制将小表广播到各个节点上,以进行join的。但是问题是,这会给Driver和Worker带来很大的内存开销。因为广播的数据要一直保留在Driver内存中。
-图3")
查看导致数据倾斜的key的数据分布情况根据执行操作的不同,可以有很多种查看key分布的方式:1,如果是Spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key分布情况。
带的CSV文件如何导入hive
1、目前使用比较顺畅的方式是通过spark-shell2, 先把Hive表转化为DataFrame,再基于DataFrame.writer.csv()DataFrameWriter.csv导出到HDFS。
2、输入配CSV input,输出配Hive output。
3、以下是一些常见的数据导入方法的比较: 通过HiveQL加载数据:Hive可以通过HiveQL语句来加载数据,无论是结构化数据(如CSV、JSON)还是非结构化数据(如文本文件)。使用HiveQL加载数据相对简单,适用于较小规模的数据集。
4、处理方式如下:先将excel表中数据另存转化为data.csv格式,转化为.csv格式的文件默认就是用“,”进行分割的,可以用notepad++打开data.csv格式查看。然后再讲数据导入到hive仓库中即可。
5、Solution 1 : 将json格式数据导入到MongoDB中,然后MongoDB可以将数据转换为CSV格式数据,然后导入到mysql中;CSSer.com采用的是wordpress程序,数据库为mysql,要想移植到MongoDB数据库,则需要进行数据转换。
6、使用文本导入向导:在Excel中选择数据选项卡,然后点击从文本。在文本导入向导中,选择txt文件并按照向导指示进行设置,确保选择正确的分隔符和数据格式。
【数仓】对比spark-hive的两种分布式计算模式
Spark on Hive是以Spark角度看Hive是数据源,在Spark中配置Hive,并获取Hive中的元数据,然后用SparkSQL操作hive表的数据并直接翻译成SparkRDD任务。Hive只是作为一个Spark的数据源。
local[ ]:启动跟cpu数目相同的 executor 上述情况中,local[N]与local[*]相当于用单机的多个线程来模拟spark分布式计算,通常用来检验开发出来的程序逻辑上有没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。
HIVE,一个数据仓库系统。它将数据结构映射到存储的数据中,通过 SQL 对大规模的分布式存储数据进行读、写、管理。 根据定义的数据模式,以及输出 Storage,它会对输入的 SQL 经过编译、优化,生成对应引擎的任务,然后调度执行生成的任务。
首先我们说一说大数据分析,现在的大数据分析体系以Hadoop生态为主,而近年来逐渐火热的Spark技术也是主要的生态之一。可以这么说,Hadoop技术只能算是以HDFS+YARN作为基础的分布式文件系统,而不是数据库。
数据仓库数据建模的几种思路主要分为一下几种 星型模式 星形模式(Star Schema)是最常用的维度建模方式。星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
到此,以上就是小编对于sparkhive的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏